Better Rater
After skimming the annual rating file of our company, my boss was kind of unpleased because some raters simply gave full marks(5 pts) to all staff working for them, or gave high scores with slight variation. But wasn’t rating supposed to reflect staff’s problem-solving capability as well as interpersonal, cross-group communication skills? If all staff’s rating score are pretty close, how can those truly excellent staff stand out? My boss asked me to help him find out those irresponsible raters.
Quick looked through all data, I found that thepattern of irresponsible raters was that they give their staff high scores with little variation then everybody was happy and no one would blame. Given that each spreadsheet had a few hundreds records and there were dozens of spreadsheets. I decided to write a script to address this pattern recognition problem.
Assume that there are two kinds of raters, responsible ones and irresponsible ones and rater’s rating with each group are i.i.d. For simplicity, let us assume they follow two different Gaussian distributions and . Then this problem becomes a clustering problem — we will classify all data to two clusters. This unsupervised learning problem can be solve using handy EM algorithm. I then used pyecharts library to visualize all data and highlighted those suspected irresponsible raters.
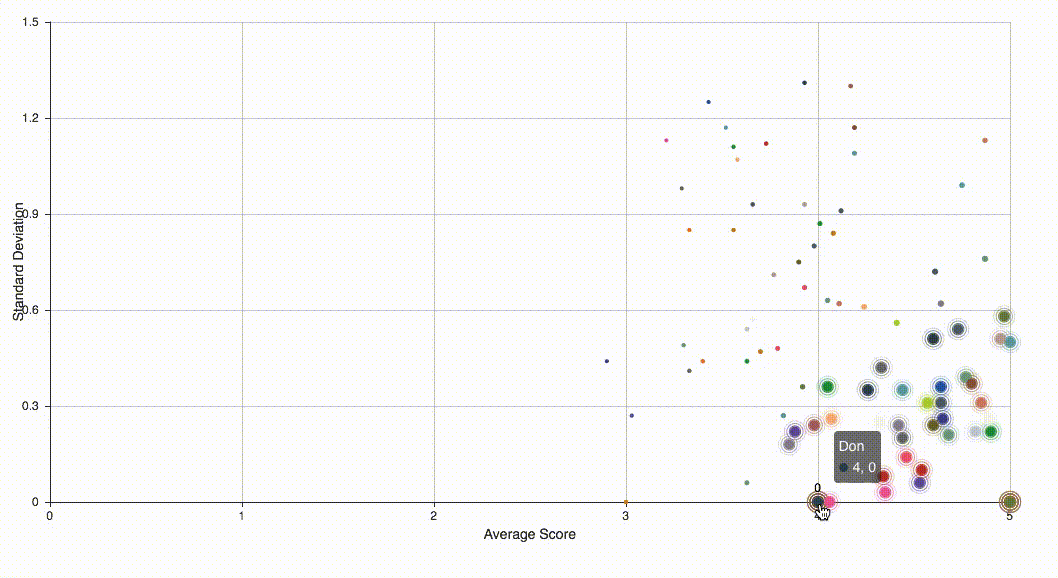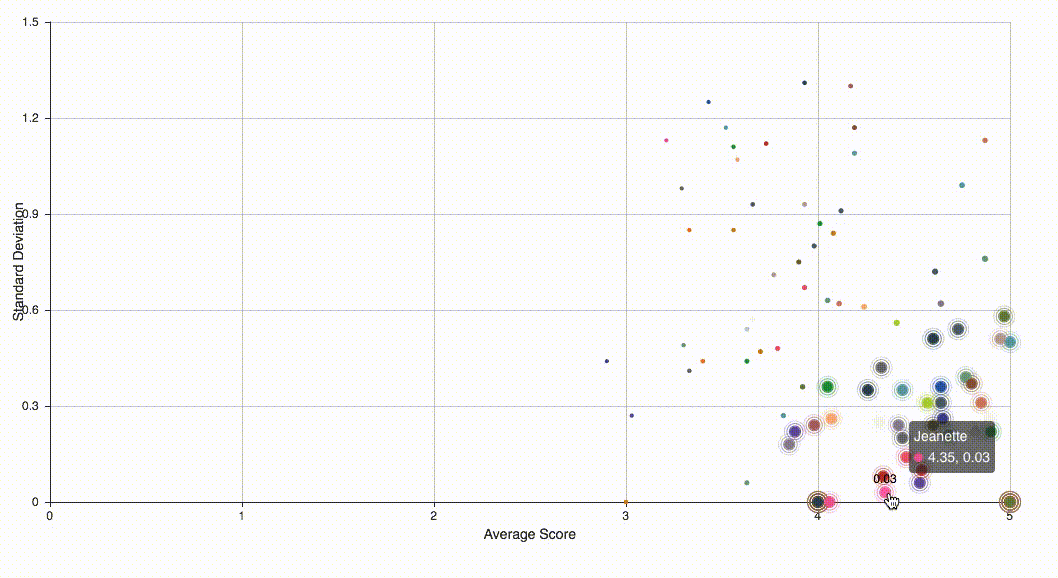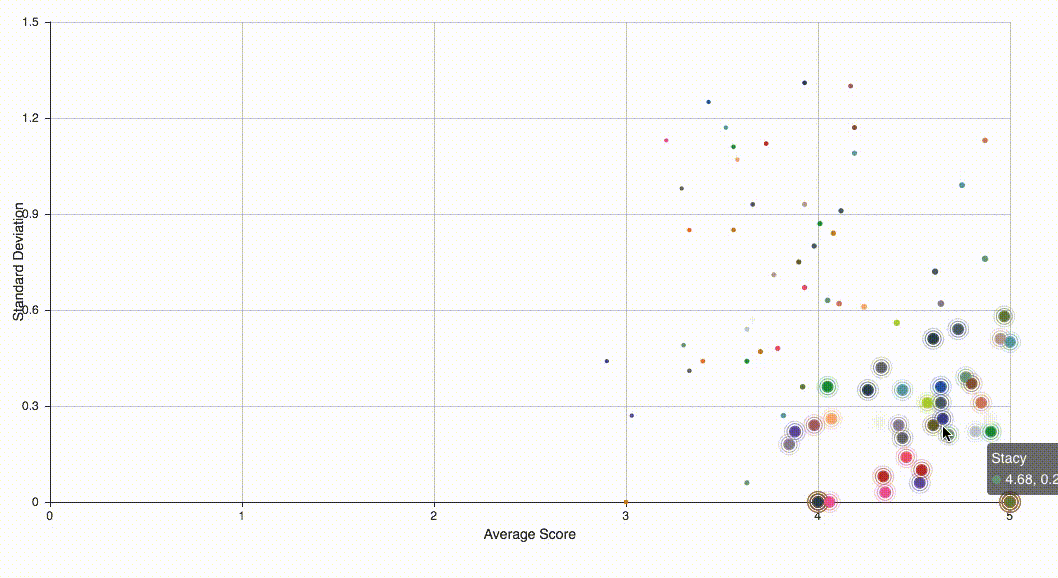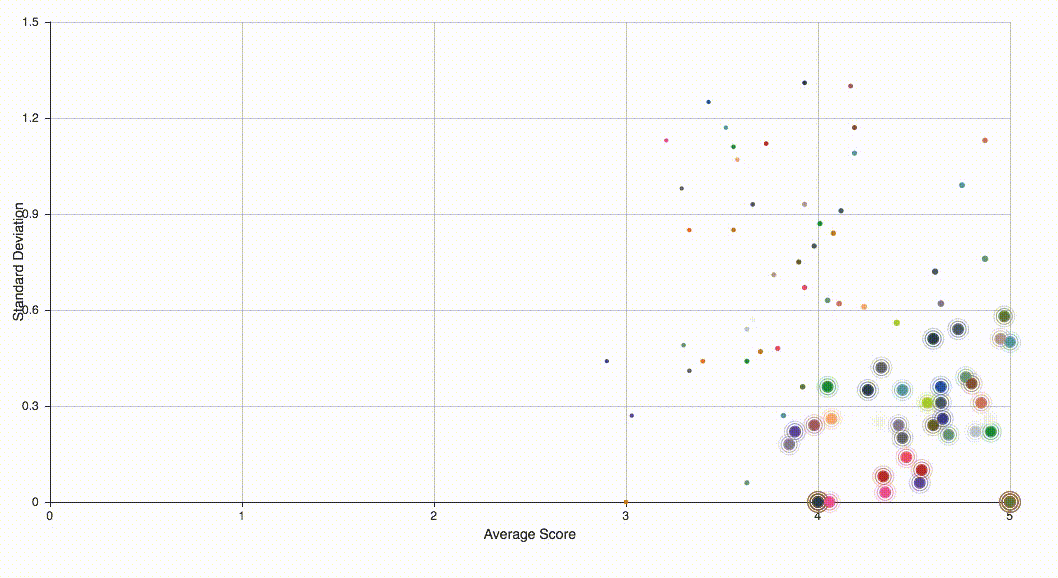
For the purpose of protecting privacy, names and data in the above figure are simulated.
If the performance of clustering is not good enough or the size is still too large, one can perform Gaussian mixture model multiple times. In fact, the above figure was generated by prefoming classfication twice.
If you have similar task to do, you may consider to use my code.